1.为什么要介绍phpquery,因为他强大:
Query的选择器之强大是有目共睹的,phpQuery 让php也拥有了jquery选择器这样的能力,它就相当于服务端的jQuery(这里主要指的选择器)。
2.它的存在意义:
我们有时需要抓取一个网站的页面内容,但只需要特定部分的信息,通常会用正则来解决,这当然没有问题。正则是一个通用解决方案,但对于一般的普通人来说正则肯定不会或者不熟练,这种情况下,怎么用更简单快捷的方法来抓取页面内容。比如你想有很多人想抓取淘宝商品的内容,也就是采集淘宝商品的属性;
3.浅谈phpquery:
phpQuery是基于php5新添加的DOMDocument。而DOMDocument则是专门用来处理html/xml。它提供了强大xpath选 择器及其他很多html/xml操作函数,使得处理html/xml起来非常方便。那为什么不直接使用呢?这个,去看一下官网的函数列表 就知道了,如果对自己的记忆力很有信心, 不妨一试。
4.下面教大家采集大家最喜欢的淘宝商品数据!
第一步:当然是下载phpquery啦,这里我们给大家整理出最新的phpquery供大家下载
<---点我下载--->
第二步:当然是引用了啊
require 'QueryList.class.php'; require 'http.class.php';第三步:找一个淘宝商品地址,采集出数据:
/**
* 合肥多元速---最专业的网页设计培训基地 欢迎大家加入
* http://www.doysu.com
* 培训咨询电话:0551-65118915 唐老师
* 多元速学员QQ交流群:316273374
*/
require 'QueryList.class.php';
require 'http.class.php';
//淘宝商品地址
$url = 'https://detail.tmall.com/item.htm?spm=a230r.1.14.9.E4XguT&id=17985838738&cm_id=140105335569ed55e27b&abbucket=19&sku_properties=5919063:6536025';
//实例化
$http = new Http();
//获取网页内容
$html = $http->get($url);
//内容转码
$html = iconv('GBK','UTF-8',$html);
//需要获取的参数
$reg = array(
'shuxing' => array('.attributes ul li','text')
);
$rang = '';
$data = QueryList::Query($html,$reg,$rang,'','UTF-8')->jsonArr;
echo "
";
print_r($data);
我们来看看我们要获取什么?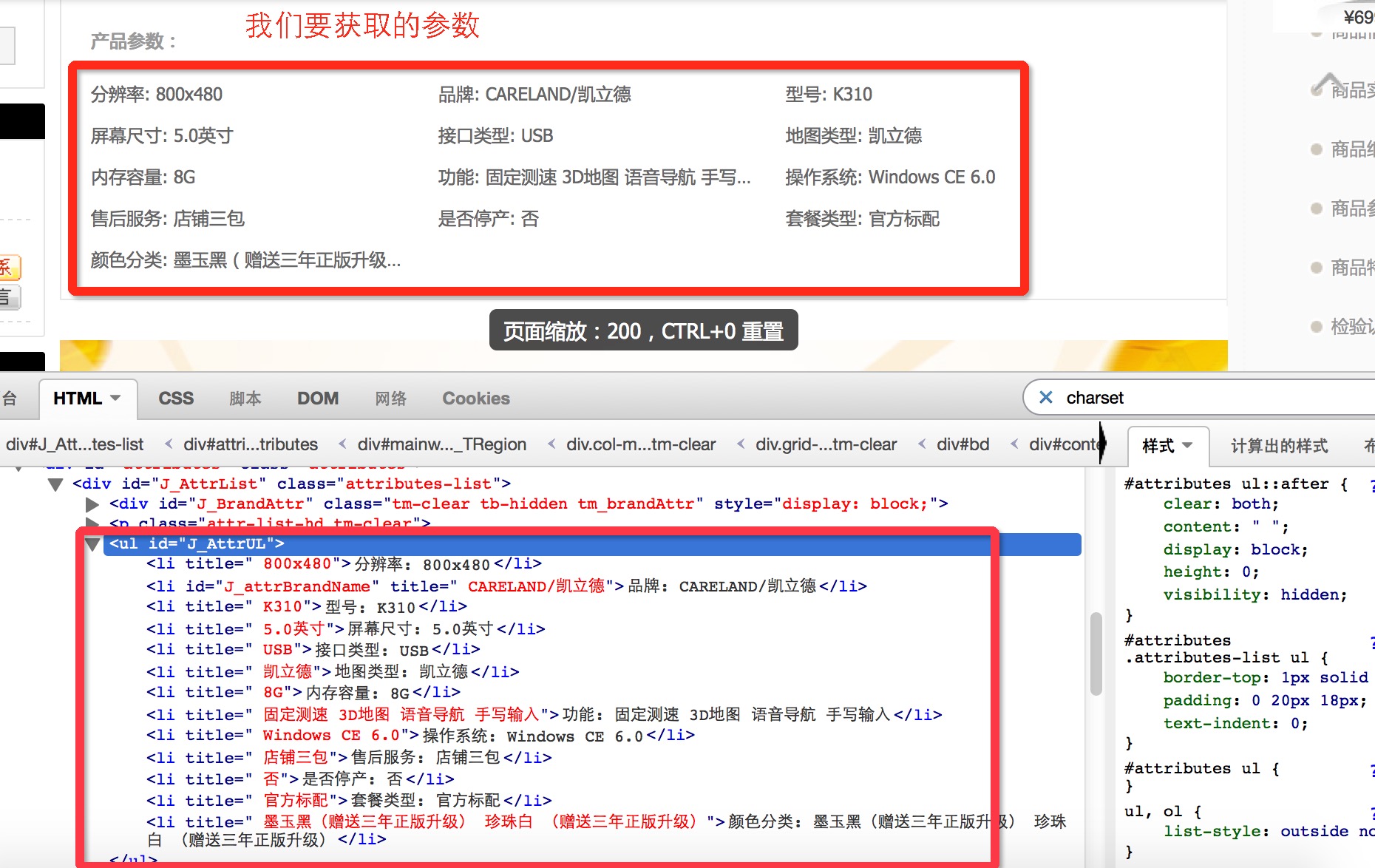
下面是详细介绍phpquery详细用法:
//获取CSDN移动开发栏目下的文章列表标题
$hj = QueryList::Query('http://mobile.csdn.net/',array("title"=>array('.unit h1','text')));
print_r($hj->jsonArr);
//回调函数1
function callfun1($content,$key)
{
return '回调函数1:'.$key.'-'.$content;
}
class HJ{
//回调函数2
static public function callfun2($content,$key)
{
return '回调函数2:'.$key.'-'.$content;
}
}
//获取CSDN文章页下面的文章标题和内容
$url = 'http://www.csdn.net/article/2014-06-05/2820091-build-or-buy-a-mobile-game-backend';
$reg = array(
'title'=>array('h1','text','','callfun1'), //获取纯文本格式的标题,并调用回调函数1
'summary'=>array('.summary','text','-input strong'), //获取纯文本的文章摘要,但保strong标签并去除input标签
'content'=>array('.news_content','html','div a -.copyright'), //获取html格式的文章内容,但过滤掉div和a标签,去除类名为copyright的元素
'callback'=>array('HJ','callfun2') //调用回调函数2作为全局回调函数
);
$rang = '.left';
$hj = QueryList::Query($url,$reg,$rang,'curl');
print_r($hj->jsonArr);
//继续获取右边相关热门文章列表的标题以及链接地址
$hj->setQuery(array('title'=>array('','text'),'url'=>array('a','href')),'#con_two_2 li');
//输出json数据
echo $hj->getJson();
下面介绍下query方法(只需要调用就行了,在QueryList.class.php文件里面):
/**
* 静态方法,访问入口
* @param string $page 要抓取的网页URL地址(支持https);或者是html源代码
* @param array $regArr 【选择器数组】说明:格式array("名称"=>array("选择器","类型"[,"标签过滤列表"][,"回调函数"]),.......[,"callback"=>"全局回调函数"]);
* 【选择器】说明:可以为任意的jQuery选择器语法
* 【类型】说明:值 "text" ,"html" ,"HTML标签属性" ,
* 【标签过滤列表】:可选,当标签名前面添加减号(-)时(此时标签可以为任意的元素选择器),表示移除该标签以及标签内容,否则当【类型】值为text时表示需要保留的HTML标签,为html时表示要过滤掉的HTML标签
* 【回调函数】/【全局回调函数】:可选,字符串(函数名) 或 数组(array("类名","类的静态方法")),回调函数应有俩个参数,第一个参数是选择到的内容,第二个参数是选择器数组下标,回调函数会覆盖全局回调函数
*
* @param string $regRange 【块选择器】:指 先按照规则 选出 几个大块 ,然后再分别再在块里面 进行相关的选择
* @param string $getHtmlWay 【源码获取方式】指是通过curl抓取源码,还是通过file_get_contents抓取源码
* @param string $outputEncoding【输出编码格式】指要以什么编码输出(UTF-8,GB2312,.....),防止出现乱码,如果设置为 假值 则不改变原字符串编码
*/
public static function Query($page, $regArr, $regRange = '', $getHtmlWay = 'curl', $outputEncoding = false)
{
if(!(self::$ql instanceof self))
{
self::$ql = new self();
}
self::$ql->_query($page, $regArr, $regRange, $getHtmlWay, $outputEncoding);
return self::$ql;
}
使用:$data = QueryList::Query($url,$reg,$rang,'curl','UTF-8');那么怎么把数据转换为数组呢?
//转换为数组
$res = $data->jsonArr;